Automating Repetetive Work With Computer Vision
2 minute TLDR
In my undergraduate honors thesis in computational neuroscience, I identified an opportunity to apply computer vision to automate 250+ hours of manual video analysis. My lab focused on the “Bayesian brain hypothesis,” the theory that humans subconsciously use Bayesian inference to form internal representations of probability distrubutions during sensory perception and learning. Participants in our study learned to classify novel objects based on their sense of touch through hundreds of repeated trials. I aimed to automatically segment video of participants performing the experiment into “during-trial” and “between-trial” regions to analyze the duration of hand-object contact.
Key Achievements:
- First Attempt: Frame Classification and Time-Series Segmentation
- Used an image classification model to determine probability of "hand-object contact" frame by frame.
- Combined these frame-wise predictions with time-series segmentation; Initial results were promising, but the image classifier faced challenges generalizing to unseen participants.
- Second Attempt: Object Detection and Post-Processing
- Leveraged an object detection model trained on a public dataset, avoiding the need for hand-labelling training data.
- Developed domain-specific post-processing steps reduce false positives.
- Achieved 87% frame-wise classification accuracy and very strong qualitative results.
- Encountered "over-segmentation errors," causing poor performance on temporally-sensitive evaluation metrics.
- Promising future directions:
- Proposed a method to use existing models, which are trained on public datasets, to generate high quality training data for specialized task-specific models based on open source models.
- I strongly suspect that my proposed method for automatically extracting high-quality training data for use in semi-supervised learning would succesfully convert the strong frame-wise performance to strong whole-sequence performance.
Results:
The prototype exhibited strong qualitative results, showing clear potential to automate video segmentation. Over-segmentation errors and trial start prediction inaccuracies highlight areas for refinement. Future directions include integrating temporally-aware open source models through the pipeline I propose which automates high-quality data labeling for semi-supervised learning.
This project demonstrates the value of cross-disciplinary problem-solving, combining various areas of machine learning and statistics (human-object interaction, temporal action segmentation, time series segmationation), to answer scientifically-relevant questions.

Okay, onto a full explanation, because this hand-object contact stuff probably sounds a little weird without context. Let’s start with the experiement the lab was running, and why automating this video processing would be so helpful.
What was the lab studying?
My project investigated an area of computational neuroscience called the “Bayesian brain hypothesis” which posits that the human brain is a machine which makes “Bayes-optimal” inferences: the statistically optimal combination of all present information and previous knowledge.
My research group focused on Bayesian modeling of human tactile perception. We set up an experiment to examine whether the human brain unknowingly uses Bayesian inference to form an internal representation of probability distributions using tactile information. We had participants complete a haptic categorization task which entailed both learning and sustained performance after learning, and compared human performance to a series of Bayesian models which were simulated to complete the same task.
This research on human subconscious statistical learning was very interesting, but the focus of this blogpost is on my journey towards using computer vision to automate 250+ hours of video analysis collected for this experiment. Here, I will give a brief overview of our experiment which will be sufficient to highlight the relevance and scope of computer vision in my research.
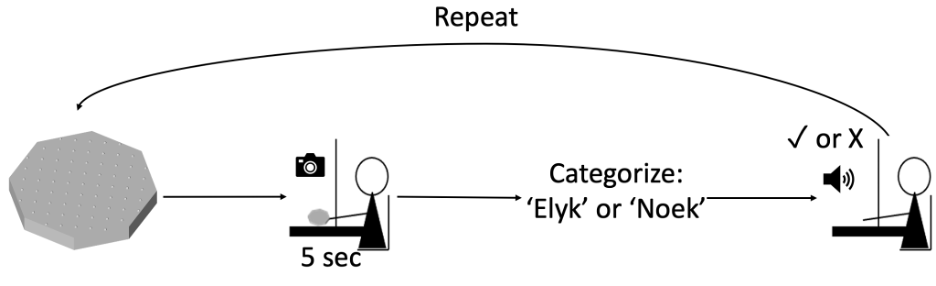
During the experiment, participants sat behind an opaque screen that hid their hands from view, allowing them to feel but not see the stimuli. On each trial, participants were presented with a randomly selected object from a collection of 25 novel stimuli. These objects are roughly the shape of a large coin, and differ by the number of sides and by the density of dots on one face. Participants had the goal on each trial to correctly classify the object into one of the novel categories “Elyk” or “Noek” (Figure 2). Participants were informed whether their classification was correct after each trial. At the start of the experiment, participants would guess randomly the category of each stimulus; however, as they repeatedly guessed a stimulus’s category and received feedback, they improved their performance over the course of the experiment.
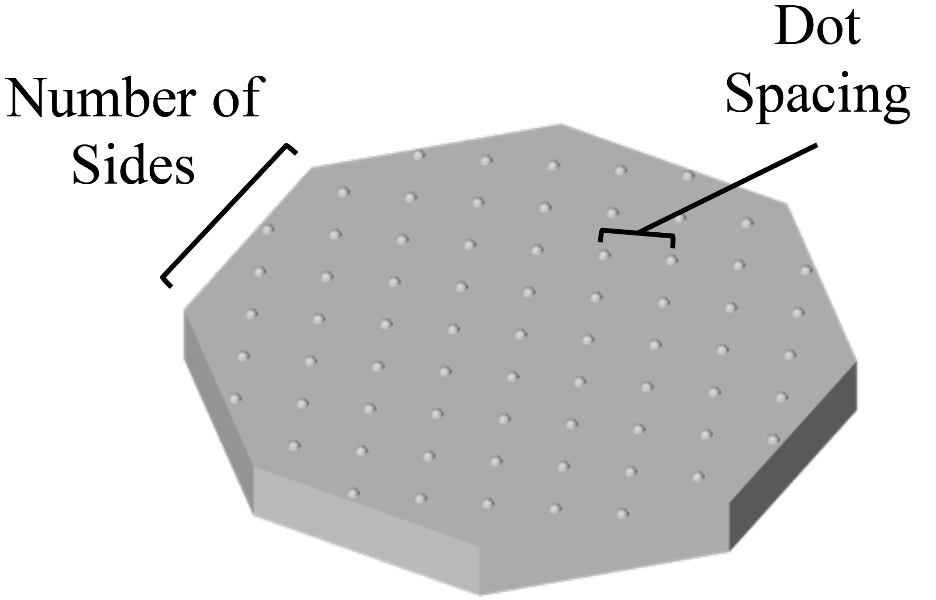
The learning task was inherently challenging because the “Elyk” and “Noek” categories we made for the objects were defined according to 2D Gaussian distributions (one dimension for number of sides, the other for dot spacing). Participants had 5 seconds to feel the stimulus on each trial, and were informed by a beep that they should put the object down when their time was up. Sometimes participants identified the category of the stimulus in less than 5 seconds, and sometimes they took longer than 5. This led us to wonder what factors influence how long participants feel the object on each trial. In order to identify these factors, we needed to determine how long participants held stimuli in each trial.
Manually labeling all of the videos we collected during the experiments is practically infeasible, so I aimed to create a computer vision system which could automatically detect the duration of each trial.
My goal
How can I automatically segment video of a participant completing the experiment into distinct temporal regions: during a trial, where the participant is touching the object, and between trials, where the experimenter switches the object in front of the participant?

Preliminary work: automatic video zooming
I made a simple tool to automatically zoom videos to only focus on hands. By ensuring that the hands were in the center of every video, I could remove most of the pixels irrelevant to the task, thus speeding up processing time. I used the mediapipe library to detect the hands in the video.
Solution attempt 1 (unsuccessful):
Not long before I realized that the lab would benefit from this computer vision system, I developed my “What Bird is That” project, which involved using a machine learning model which can identify the species of bird in a photo. The computer vision system for this project was a straightforward image classification model, one of the most foundational tasks in computer vision. In order to train that model, I used a dataset with thousands of photos of birds and labels indicating their species.
With this experience in mind, I wondered if I could extend this approach, combined with time series analysis, as a technique to solve our problem. Of course, my bird species identifier only analyzed images, whereas this task for the lab involves video. Here is an overview of the method I proposed.
- Manually label frames in a training set as containing “hand-object contact”
- Train an image classification model to identify whether there is participant hand-object contact in an image
- Extract all of the frames from a video, and have the model assign probability of participant hand-object contact in each frame
- Use a time series segmentation algorithm on the time series of single-frame contact probabilities to determine sustained periods of contact and non-contact
In pseudocode:

Time series segmentation
Setup of the problem: The output of the image classifier is a univariate time series representing the probability of contact in \(T\) frames, \(y=\{y_1, y_2,…,y_T \}\). Videos of participants were collected in groups of 5 trials, so there should be 10 changepoints in each video; however, the first time the participant picked up the stimulus was cut off at the start of some videos, resulting in 9 changepoints in those videos. I therefore conceptualized the problem as having \(K^*\) unknown changepoints \(\{\tau_1,\tau_2, …, \tau_{K^*} \}\) where \(K^* = 9\) or \(K^* = 10\).
We hope that the time series of image probabilities generated by the image classifier alternates between two stationary distributions: one which occurs during a trial (during hand-object contact) and the other between trials:

A selective review of offline change point detection highlights that the Pruned Exact Linear Time (PELT) algorithm finds the optimal solution to the segmentation problem with unknown numbers of changepoints (Truong et al., 2020; Killick et al., 2012). The ruptures Python package provides an easy-to-use implementation of PELT and related time series segmentation algorithms.

Results
I hand labeled transition frames for 4 minutes of an 8-minute 60fps video. I trained a similar image classifier to the one I used in my “What Bird is That” project (that project used EfficientNet, and I experimented with EfficientNet and EfficientNetV2 here).

I used the image classifier to predict the probability of contact in the portion of the video which was not in the training set. I then used PELT to segment this time series of predictions. The preliminary results looked very strong in this case where (Figure 6) I trained the image classifier on a segment of the test video.
After these preliminary results, I trained the image classifier on video from 3 additional participants. Unfortunately, the image classifier trained on additional data didn’t generalize well to new participants.

Solution attempt 2 (working prototype)
A hand-object interaction dataset with 100,000 annotated images provides bounding boxes around hands and the objects with which they are in contact (Shan et al., 2020). The model distinguishes between stationary objects (e.g. tables and furniture) and portable objects which can be moved by hands, and it is built on the Faster R-CNN object detection network (Ren et al., 2015), which obtains strong results.
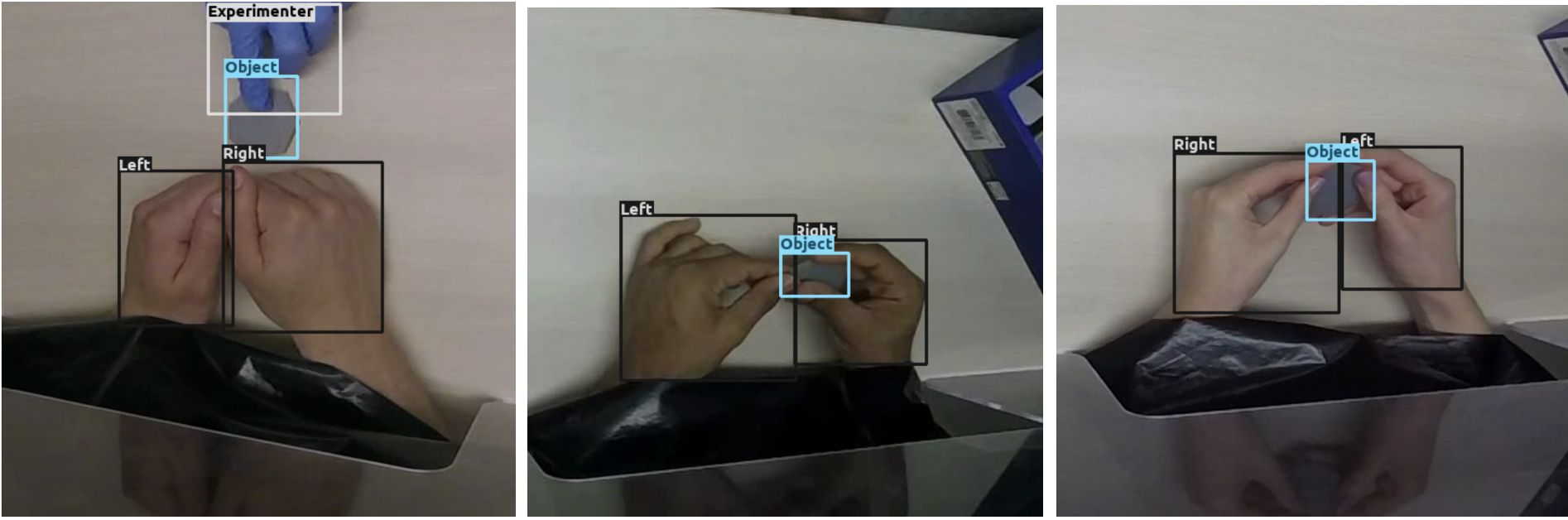
I applied this object detection model (Shan et al., 2020) on frames extracted from participant videos. I added a post-processing step to reduce false positives caused by the algorithm detecting the experimenter’s hand in contact with the stimulus.
Had I not added this step, then the algorithm would falsely report the hand-object contact associated with a participant being mid-trial when the experimenter is swapping the stimulus between trials. I identified frames in which an experimenter was holding the object by recognizing that experimenters wore blue latex gloves. Thus, if more than half of the pixels in a bounding box are blue, then I’d identify that the hand belongs to the experimenter.

To account for different lighting conditions, I determined that a pixel was blue, and therefore part of an experimenter’s blue latex gloves, if the pixel has HSV color code between (90, 50, 50) and (130, 255, 255).

I also briefly tried an egocentric hand-object segmentation model (Zhang et al., 2022) (which is shown in the video at the top of this page), although it had worse performance than the object detection model I ultimately used (Shan et al., 2020). My application doesn’t require the fine-grained pixel-wise predictions of image segmentation, so I stuck with the more accurate image classifier.
Solution attempt 2 results:
As is common in the Temporal Action Segmentation literature (Ding et al., 2024), I used both a quantitative and qualitative evaluation to determine the quality of my results. My method had strong qualitative results, but was prone to “over segmentation errors,” which resulted in poor results on temporally sensitive quantitative evaluation metrics. This is clear when we look at whole-sequence qualitative results (Figure 12).

From Figure 12, we can clearly see that on aggregate, the algorithm’s predictions are close to the ground truth. In fact, the algorithm correctly detected the class of 87% of the 87,352 labeled frames I tested. The small jitters in which the predicted class rapidly switch between mid-trial and between-trials are called “over segmentation errors,” and are a well-documented challenge in the temporal action section literature (Ishikawa et al., 2021; Xu et al., 2022; Ding et al., 2024). These over segmentation errors are the primary reason why I say that my algorithm exhibits strong preliminary results.
The top result in Figure 12 demonstrates another type of common error: the model predicts that a trial begins later than it should. This error is partly a matter of definition of when a trial starts. After some discussion, my supervisor decided that we should denote the beginning of a trial as soon as the participant begins to touch the stimulus, rather than once they’ve lifted it off of the table.
The model tends to erroneously predict that the trial starts late because at the start of hand-object contact, the model detects the participants’ hands resting on the table, but does not properly detect the stimulus which is on the table; rather, it predicts that the stimulus is part of the table while the participant has not lifted the stimulus off of it. The object detection model distinguishes between portable objects (like our stimuli) and stationary objects (like the table on which the participants rest their hands) (Shan et al., 2020). When the stimulus is still on the table and the participant is touching it, the object detection model can often draw a bounding box around the table, and predict that the participant is touching a stationary object: it fails to identify that the participant is touching a thin portable object which is itself in contact with a stationary object.
Next steps
Alleviating trial initiation prediction errors
To alleviate this error, I think that I could train an object-detection algorithm specifically designed to recognize our stimuli. In this way, we could detect when there is overlap between a detected hand and a detected stimulus, facilitating the inference that there is hand-object contact in that frame. Creating training data for an object detection model is usually time-consuming; however, the current model I used (Shan et al., 2020) can already accurately identify our stimuli in many situations. The stimuli which are detected by the current object detection algorithm can be used as training data for a stimulus-specific object detector. I can use heuristics to improve the quality of these automatically generated labels to ensure that only quality samples are used to train this domain-specific object detector:
- Only accept bounding boxes for stimuli which have similar length and width. This object detector is intended to work.
- Only include objects detected which have a bounding smaller than hands detected in the smaller frame.
These two heuristics would prevent the poorly-identified objects in Figure 13 from being included as training data for this new object detector.

Alleviating over segmentation errors
Over segmentation errors are the primary issue with the algorithm I developed. In my thesis, I proposed multiple methods which I expect would resolve the issue in this context.
Some over-segmentation errors arise because our algorithm is not temporally-aware: it classifies each frame individually, without taking account of context from surrounding frames. An ideal system would be able to recognize that if a participant picks up the object, and manipulates it in a way which causes it to be briefly hidden from the camera, then they probably did not drop the object and pick it back up very quickly.
In the temporal action segmentation literature, “timestamp supervision” refers to a specific type of semi-supervised learning, where most training data is unlabeled, but in each video, there is (at least) one frame with a class label and the label’s associated timestamp (Li et al., 2021; Ding et al., 2024).
I propose that a temporal action segmentation model which requires timestamp supervision could be trained on a dataset that is automatically generated using my current system. A dataset with timestamp supervision does not require labels on every frame in videos which serve as training data. This is a key insight, and allows me to extract a small number of labels from the system’s predictions to form this training dataset.
To automatically generate this training set, my current model will predict the class of every frame in the entire dataset, and extract only the frames where we are most confident about the model’s predicted labels according to a simple heuristic. This would be done on video for which there are no ground truth labels.
Figure 14 shows both the model’s predicted labels and ground truth labels from a part of a video. The black dotted lines represent frames about which we have the highest prediction confidence because they are in the middle of a sequence of a single predicted class.
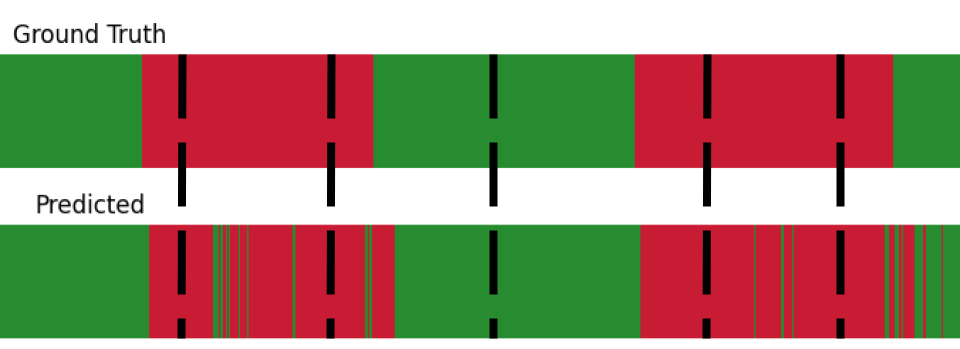
This simple heuristic of only extracting frames which are closest to the middle of a long sequence would likely be sufficient to identify frames which mostly belong to their predicted class. Over-segmentation errors from the current model are unlikely to meaningfully affect this method of generating training data. This is important because these over-segmentation errors which this technique sidesteps are a primary factor which influence our model’s poor performance in temporally-aware evaluation metrics.
Other future directions
If you’ve read this far, I’m very impressed! I also thought about a few other future directions including the following. Feel free to ask me about these:
- Image classifier-based method using I3D for temporally-sensitive feature extraction (Carreira & Zisserman, 2017).
- Simple processing on existing outputs: smoothing the time series (perhaps with a convolution?), then apply time series changepoint detection with PELT or similar.
- Retrain the hand-object interaction model I used (Shan et al., 2020) but use feature extraction from I3D. This would likely help because that work was focused on object detection in single images, rather than sequences.
- Snorkel (Ratner et al., 2017) could be used in conjunction with my proposed methods for automatically generating training data for use with specialized models.
- I need to learn more about Snorkel and how it quantifies uncertainty from automatic labelling functions.
References
-
- Optimal Detection of Changepoints with a Linear Computational CostJournal of the American Statistical Association, 2012
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal NetworksIn Advances in Neural Information Processing Systems, 2015
- Temporal Action Segmentation: An Analysis of Modern TechniquesIEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
- Alleviating Over-Segmentation Errors by Detecting Action BoundariesIn 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), 2021
- Don’t Pour Cereal into Coffee: Differentiable Temporal Logic for Temporal Action SegmentationIn Advances in Neural Information Processing Systems, 2022
- Temporal Action Segmentation from Timestamp SupervisionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
- Snorkel: Rapid Training Data Creation with Weak SupervisionProceedings of the VLDB Endowment, 2017